
KI-Modelle – allen voran grosse Sprachmodelle – müssen im Rahmen ihres Trainings viele Daten sehen, damit sie die für ihre Funktion nötigen Konzepte in ihren Parametern abbilden können. Hierfür werden vor allem öffentlich zugängliche Inhalte verwendet, und zwar ohne zu Fragen. Doch ist das erlaubt? Wir haben das analysiert – mit einem Fokus auf Schweizer Recht, aber unsere Überlegungen mögen auch die Diskussion auf europäischer Ebene inspirieren. Der Überblick in diesem Teil 26 unseres Blogs über verantwortungsvollen Einsatz von KI. In jedem Fall: Die Schweiz ist ein gutes Pflaster für das Training von LLM.
Die Vorstellung, dass grosse Sprachmodelle sich alle Inhalte merken, die ihnen beim Training gezeigt werden, ist ein grosses Missverständnis. Das ist weder das Ziel noch wäre es besonders effizient. Vielmehr merkt sich ein Modell beim Training jene sprachlichen und inhaltlichen Konzepte, die es besonders häufig sieht. Dabei kann es durchaus zur wortwörtlichen oder auch inhaltlichen sog. Memorisierung kommen, wenn es immer wieder demselben Slogan begegnet oder eine bestimmte Information in zahlreichen Unterlagen sieht. Der Normalfall ist das allerdings nicht; schliesslich soll ein Modell neue Inhalte generieren, nicht einzelnes Gelerntes rezitieren. Doch dort, wo es zur Memorisierung kommt, stellt sich die Frage, was dies aus rechtlicher Sicht für das Training und die Weitergabe solcher Modelle bedeutet.
Wir haben diese Frage (einschliesslich die Beurteilung der dem eigentlichen Training vorangehenden Bearbeitungsschritte) mit Fokus auf das Schweizer Recht im Zusammenhang mit einem entsprechenden Projekt des ETH AI Centers eingehend analysiert und sind zum Schluss gekommen, dass allen Unkenrufen zum Trotz selbst eine Memorisierung dem Training, insbesondere von grossen Sprachmodellen mit öffentlichen Inhalten, nicht entgegensteht. Die Details sind in einem wissenschaftlichen Beitrag, den ich mit meinem Kollegen Livio Veraldi verfasst habe, ausführlich dargelegt, kürzlich erschienen im Jusletter auf Deutsch und Jusletter IT auf Englisch.
Urheberrecht anpassen: Den Sack schlagen und den Esel meinen?
Das Urheberrecht sorgt für die meisten Diskussionen, was vor allem daran liegt, dass es hier auf den ersten Blick um besonders viel geht: Inhaber von Inhalten und Kreativschaffende wollen nicht, dass die Früchte ihrer Arbeiten ohne ihre explizite Zustimmung und vor allem ohne Abgeltung durch die grossen KI-Player verwendet werden. Demgegenüber befürchtet die KI-Forschung und -Entwicklung, dass ohne Zugang zu Inhalten die Weiterentwicklung der Technologie, und im Falle der Schweiz, auch der Wirtschaftsstandort Schweiz gefährdet ist.
Diese Themen sind rechtspolitisch zu entscheiden; wichtig scheint an dieser Stelle allerdings der Hinweis, dass in der Schweizer Medienszene die Bedrohung durch US-Tech-Konzerne weniger im Training von Sprachmodellen mit "alten" Inhalten gesehen wird, sondern von Geschäftsmodellen, bei denen KI-gestützte Anwendungen aktuelle Informationen – wie etwa Medienberichte – als Rohstoff ohne angemessene Abgeltung zu neuen Produkten verarbeiten, aber in Konkurrenz zu den traditionellen Medienhäusern. Für einen solchen Rechtsstreit braucht es keine Anpassung des Urheberrechts, weil es diese Fälle heute schon erfassen kann – insbesondere, wenn sich KI-Anbieter ohne Erlaubnis an Inhalten hinter Bezahlschranken bedienen.
Derweil dürfte es Kreativschaffenden vor allem um die KI als Konkurrenz gehen, die Inhalte günstiger herzustellen vermag und dadurch auf Kreativschaffende wirtschaftlichen Druck ausübt. Das tun andere Künstler zwar auch, und auch sie müssen wie die KI anhand bestehender Werke lernen, wie dies geht bzw. werden in ihrem Tun von bestehenden Werken inspiriert, aber das geschieht alles mit sehr viel weniger Hebelwirkung und ist weniger effektiv. Dies ist jedoch keine Frage der Verletzung des Urheberrechts, sondern letztlich eine wirtschaftspolitische - jedenfalls wenn der Output der KI keine Urheberrechte verletzt. Die Gegenstimmen führen ins Feld, dass die Schweiz durch eine strengere Regulierung nur zu verlieren hat: Für Kreativschaffende ist dadurch nichts gewonnen, denn die Mehrheit der Modelle stammt aus Ländern, in denen kaum Einschränkungen existieren (USA, China), und die Schweiz als Standort für KI-Forschung und damit der Nukleus der Innovation an Attraktivität verliert.
Urheberrecht: Keine relevante Werknutzung, Forschungsausnahme greift
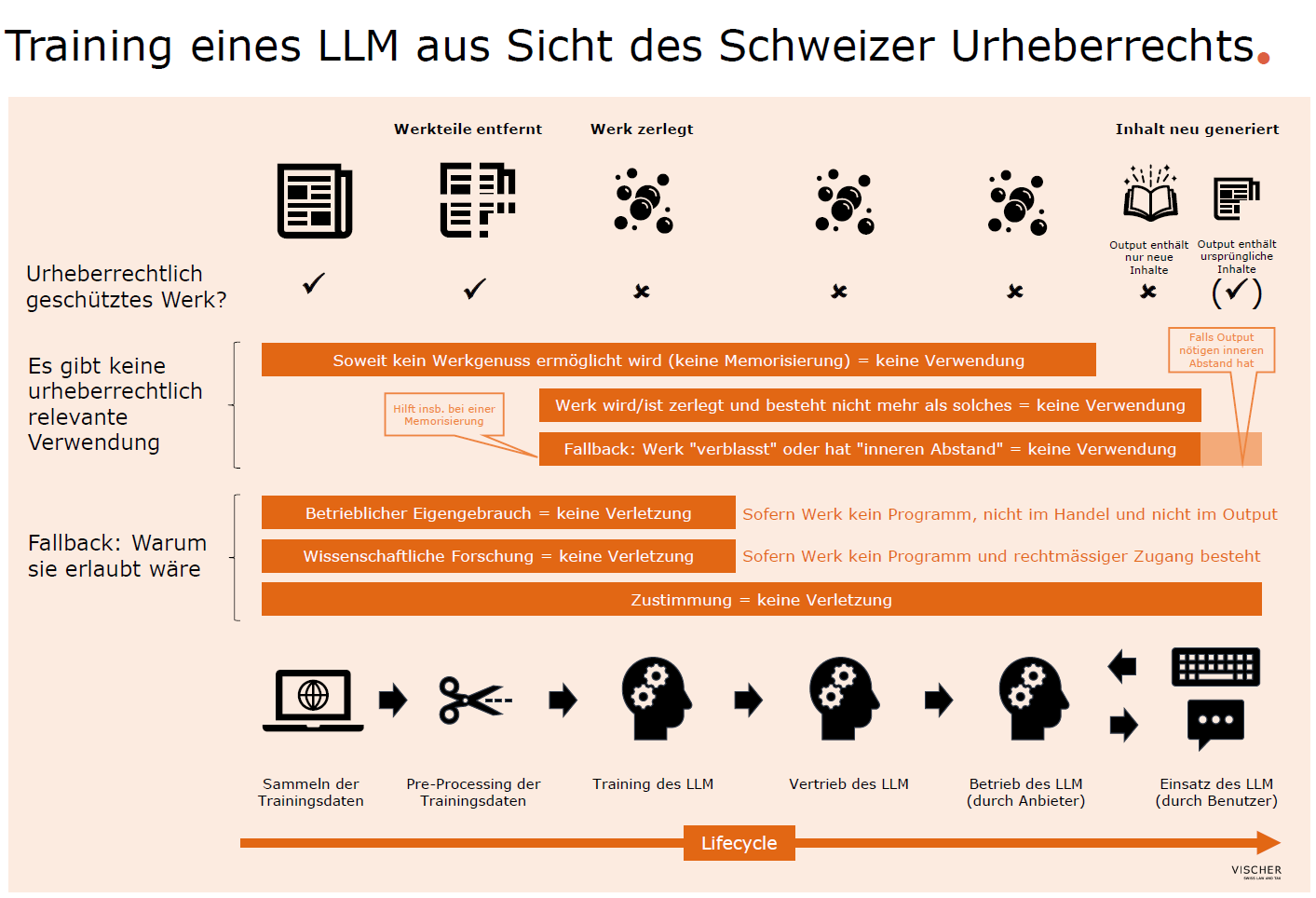
Aus rein rechtlicher Sicht ergab unsere Analyse, dass sich die Zulässigkeit des Trainings etwa von grossen Sprachmodellen mit öffentlichen Inhalten mit und ohne Memorisierung auf drei Ebenen ergeben kann:
- Das Training stellt keine urheberrechtlich relevante Handlung dar. Diese – auf den ersten Blick kontraintuitive Schlussfolgerung – ergibt sich in einem ersten Ansatz, wenn wir uns bewusst werden, dass nur Werkverwendungen urheberrechtlich erfasst sind, die letztlich den menschlichen Genuss eben dieser Werke ermöglichen. Dies geschieht jedoch gerade nicht. Auch im Falle einer Memorisierung liegen diese Werke im Modell technisch nicht in einer Form vor, die den menschlichen Werkgenuss ermöglicht. Erst in Kombination mit einem passenden Prompt ist es überhaupt denkbar, dass ein bestimmter Output erzeugt wird, bei dem ein Werkgenuss überhaupt ein Thema sein kann. Ein zweiter Ansatz kann sein, dass wir es mit dem eigentlichen "Werkgenuss" der KI zu tun haben, der – analog zum menschlichen Werkgenuss – urheberrechtlich frei sein muss. Wie auch ein Mensch zuerst diverse Werke konsumiert haben muss, um überhaupt im Stande zu sein, eigene Werke zu schöpfen, ist auch die KI darauf angewiesen, im Rahmen des Trainings (mitunter urheberrechtlich geschützte) Inhalte zu konsumieren, um überhaupt einen Output generieren zu können. Die Frage, wie ein so trainiertes Modell später benutzt wird, ist – wie beim Menschen - eine davon zu trennende Frage. Der dritte, von uns aufgezeigte Ansatz basiert auf der Erkenntnis, dass das, was nach dem Training im Modell enthalten ist, nicht mehr als Werk gelten kann, selbst wenn es zu einer Memorisierung kommt. Das liegt einerseits daran, dass jedes für das Training verwendete Werk in seine (urheberrechtlich nicht mehr relevanten) Bestandteile zerlegt wird, und diese Bestandteile mit den Bestandteilen aller anderen zerlegten Werke quasi zu einer Suppe vermischt werden. Auch hier ändert der Umstand, dass im Falle einer Memorisierung mit dem richtigen Prompt aus dieser Suppe wieder einzelne Teile wie bei einem Mosaik zu einem Werk zusammengefügt werden können, nichts. Dieses Zusammenfügen wäre vielmehr eine erneute und eigenständige "Schöpfung" des Werks. Selbst wenn davon ausgegangen würde, dass im Modell ein Werk quasi auf einer Meta-Ebene noch vorhanden wäre, müsste zugestanden werden, dass ein solches Werk bei der Betrachtung des Modells als Ganzes so sehr in den Hintergrund rückt, dass es in Bezug auf seine individuellen Züge verblasst und daher urheberrechtlich nicht mehr relevant ist. Mindestens aber wird sein Vorkommen als Wissen im Modell den nötigen "inneren Abstand" zum Originalwerk aufweisen, um aus diesem Grund nicht mehr urheberrechtlich relevant zu sein.
- Es greift (meist) die Wissenschaftsschranke. Selbst wenn das Training eines grossen Sprachmodells als urheberrechtlich relevante Vervielfältigung zu qualifizieren ist, wird es regelmässig von der sog. Wissenschaftsschranke (Art. 24d URG) erfasst sein. Diese Schranke setzt zwar einen rechtmässigen Zugang zu den Inhalten voraus, aber etwaige vertragliche Beschränkungen, die eine Verwendung zu Trainingszwecken untersagen, dürften regelmässig unwirksam sein. Und ein Opt-out-Recht, wie es das EU-Urheberrecht im Rahmen der dortigen "Text and Data Mining"-Regelung (TDM) kennt, gibt es in der Schweiz nicht. Die Kernfrage im Rahmen dieser Schranke, nämlich ob das Training eines Sprachmodells einen Forschungszweck darstellt, ist nach unserer Erkenntnis klar zu bejahen, wird Forschung doch als systematische, methodische Suche nach neuen Erkenntnissen verstanden – und genau darum geht es beim Training eines KI-Modells: Es soll Erkenntnisse aus den ihm vorgelegten Inhalten gewinnen. Kommerzielle Forschung ist in der Schweiz im Übrigen mitgemeint. Allerdings gilt die Wissenschaftsschranke nicht für Computerprogramme. Die andere Schrankenbestimmung, die greifen kann, ist der betriebliche Eigengebrauch, welcher Vervielfältigungen zur betriebsinternen Information und Dokumentation erlaubt. Eine Herausforderung ist dabei allerdings, dass sie für bestimmte Werkkategorien nicht zur Verfügung steht und im Handel erhältliche Werkexemplare nicht vollständig oder weitgehend vollständig vervielfältigt werden dürfen. Dem kann in der Praxis mit Anti-Memorisierungs-Techniken begegnet werden, die für einen menschlichen Nutzer relevante Teile eines Texts entfernen, ohne seinen Wert für die Maschine wesentlich zu beeinträchtigen.
- Es liegt (oft) eine implizite Zustimmung der Rechtsinhaber vor. Diese Rechtsgrundlage ist in der Praxis die schwächste, da ihr seitens der Rechteinhaber aktiv entgegengewirkt werden kann. Sie kann jedoch dort gegeben sein, wo Inhalte im Internet ohne entsprechende Gegenmassnahmen publiziert werden, weil vertreten werden kann, dass inzwischen damit gerechnet werden muss, dass sie für KI-Trainings verwendet werden.
Das Schweizer Urheberrecht weist grosse Parallelen zum Urheberrecht in der EU auf, so dass die vorstehenden Überlegungen auch für dieses Anregungen liefern können. Eine Ausnahme ist immerhin der Entscheid der Schweiz, die TDM-Regelung und insbesondere das Opt-out-Recht nicht nachzubilden. Das macht den Standort Schweiz für das Training von KI-Modellen attraktiver als die EU. Daran ändern auch die Vorgaben des EU AI Act für Allzweck-KI-Modelle nichts. Der EU-Gesetzgeber hatte zwar im Sinn, eine Regelung zu erlassen, die Nicht-EU-Anbieter von solchen Modellen zwingen sollte, sich beim Trainieren ihrer Modelle namentlich an die TDM-Regelung zu halten. Beim Verfassen der einschlägigen Bestimmung (Art. 53 Abs. 1 Bst. c AI Act) wurde jedoch nachlässig gearbeitet und übersehen, dass das EU-Urheberrecht bei einem Training in der Schweiz (oder in den USA) nicht zur Anwendung kommen will. Also kann die Nicht-Beachtung der TDM-Regelung es auch gar nicht verletzen.
Fazit: Wir sehen keinen zwingenden Anpassungsbedarf beim Schweizer Urheberrecht. Manche der Überlegungen können auch auf das EU-Urheberrecht übertragen werden, mit der grossen Ausnahme, dass letzteres mit der TDM-Regelung etwas weniger liberal ist als die Schweizer Forschungsschranke.
Datenschutz: Trainingsdaten finden meist nur anonymisiert Eingang ins Modell
Auch die datenschutzrechtliche Analyse ergibt bei genauer Betrachtung des Sachverhalts, dass ein Training von grossen Sprachmodellen nach dem geltenden Recht im Grossen und Ganzen unproblematisch ist. Hierbei muss wiederum zwischen den Fällen mit Memorisierung (Beispiel: Die grossen Sprachmodelle kennen den Geburtstag von Donald Trump, weil sie ihn genügend häufig in unterschiedlichen Quellen gesehen haben) und den Fällen ohne Memorisierung unterschieden werden.
Kommt es zu einer Memorisierung, ergibt sich die datenschutzrechtliche Zulässigkeit jedenfalls in der Schweiz grundsätzlich spätestens auf der Ebene der Rechtfertigung, und zwar aus demselben Grund, der für die Memorisierung ursächlich ist: Eine Memorisierung erfolgt normalerweise nur bei öffentlichen Personen, an denen ein entsprechendes öffentliches oder privates Interesse besteht, und zwar in Bezug auf jene Personendaten, über die entsprechend zahlreich berichtet wird. Nur in diesem Fall wird eine Information normalerweise statistisch so relevant bzw. häufig, dass sie Eingang ins Modell finden kann. Schwindet dieses Interesse, wird auch die Wahrscheinlichkeit schwinden, dass überhaupt je ein Prompt formuliert wird, der zu einer Generierung von entsprechendem Output führt. Ohne solchen Prompt gibt es aber auch keinen Output und damit keine Personendaten. Wir haben das schon in unserem Blog 19 und Blog 21 ausführlich dargelegt, und zwischenzeitlich scheint sich diese Ansicht durchzusetzen.
Kommt es nicht zu einer Memorisierung, ist die Datenschutzkonformität der Verwendung zum Training noch offenkundiger: Zwar werden Personendaten verwendet, wenn mit öffentlichen Inhalten trainiert wird, aber die einzelnen Personendaten spielen keine eigenständige Rolle, sondern werden im Sprachmodell quasi zu übergeordnetem Sprach- und Allgemeinwissen aggregiert, faktisch also anonymisiert. Selbst wenn – wie in unserem Beitrag zeigen – von einer Verletzung der Bearbeitungsgrundsätze ausgegangen würde (z.B. des Grundsatzes der Transparenz), wäre diese Verletzung durch den Rechtfertigungsgrund der Bearbeitung zu nicht personenbezogenen Zwecken gerechtfertigt. Diese Bearbeitung wird mit dem Hauptzweck der Daten regelmässig kompatibel sein.
Auch die Verhältnismässigkeit stellt in der Regel kein Problem dar: Erstens gilt bei Sprachmodellen je mehr Daten, desto besser, und zweitens werden die Personendaten als solche durch das Training aufgelöst, wie die Zutaten einer Suppe, die sich nicht mehr einzeln nachweisen lassen, aber zum Geschmack insgesamt beitragen. Auch sonst erscheint das Training eines Sprachmodells nicht als treuwidrig: Es werden nicht die einzelnen Personendaten auswendig gelernt, sondern es werden Texte analysiert, um daraus Sprach- und Sachwissen abzuleiten. Das ist ein legitimer Zweck, den der Gesetzgeber – wie beim Urheberrecht gezeigt – sogar fördern will. Dass dabei auch inhaltlich unrichtige Daten bearbeitet werden, tut der Sache ebenfalls keinen Abbruch. Erstens werden diese in der Regel nicht memorisiert, weil sie nicht durchgängig vorkommen, und wo sie dies trotzdem tun, macht das Training zweitens genau das, was der Zweck verlangt: Es bildet im Modell das korrekt ab, was im Training gesehen worden ist. Insofern ist die Datenbearbeitung für sich betrachtet akkurat. In solchen Fällen ist das eigentliche Problem nicht das Modell, sondern seine Verwendung. Dasselbe gilt für Halluzinationen: Nicht das Modell enthält falsche Informationen, sondern das Alignment des Modells, welches es dazu bringt eine Antwort auch dann zu liefern, selbst wenn es keine faktische Grundlage dafür hat.
Unsere Analyse basiert auf dem Schweizer Recht, kann aber über weite Strecken auch für die DSGVO herangezogen werden, mit der Einschränkung, dass für das Training dort per se ein Rechtsgrund erforderlich ist. Dieser wird regelmässig das berechtigte Interesse sein. Lassen sich besondere Kategorien von Personendaten im Training nicht ganz vermeiden, bietet sich insbesondere die Veröffentlichung durch die betroffene Person oder die Forschungsausnahme als Erlaubnistatbestand an, wobei hierbei womöglich sogar eine Parallelwertung zum Urheberrecht greifen kann. Dem sind wir in unserem Beitrag allerdings nicht auf den Grund gegangen. Für das Training von Sprachmodellen in der Schweiz durch Institutionen in der Schweiz ist die DSGVO unbeachtlich.
Nicht vergessen: Lauterkeitsrecht und Vertragsrecht
Unter die Lupe genommen haben wir weiter das Lauterkeitsrecht, das in der Diskussion um das KI-Training neben dem Urheberrecht etwas zu Unrecht ein Schattendasein fristet. Auch das Lauterkeitsrecht sieht Regelungen gegen die unbefugte Übernahme von fremden Arbeitsergebnissen vor. Die Erkenntnis, dass das Training von Sprachmodellen zur Abstrahierung von Informationen aus dem Trainingsmaterial führt, spielt auch hier eine entscheidende Rolle. Dieser Umstand grenzt nämlich das Training von der Übernahme eines konkreten geistigen Produkts als solches ab. Es wird also nicht ein Arbeitsergebnis verwertet, sondern "nur" die Erkenntnisse daraus – und auch diese nur, wenn sie statistisch relevant sind, also zum allgemeinen Sprach- und Sachwissen gehören, das nicht monopolisierbar ist.
Doch wie verhält es sich, wenn der Betreiber einer Website einen maschinenlesbaren Vermerk anbringt, wonach Crawler und Scraping untersagt wird? Solche Vermerke stehen dem Training eines Sprachmodells nicht unbedingt entgegen. Im Urheberrecht wird – wie gezeigt – ohnehin mit Konzepten gearbeitet, bei denen es auf den Rechteinhaber und seinen Willen nicht ankommt. Datenschutzrechtlich kann ein Crawler-Verbot zwar ein Widerspruch sein, aber dazu müsste es von der betroffenen Person selbst kommen, was regelmässig nicht der Fall ist und selbst wo es greift, gibt es regelmässig ein überwiegendes Interesse. Im Lauterkeitsrecht wiederum ist nicht ein Crawler-Verbot entscheidend, sondern die Frage, ob die Voraussetzungen der abschliessenden und engen Tatbestände erfüllt sind.
Bleibt noch die Vertragsverletzung als Einfallstor derjenigen, die sich gegen eine Verwendung ihrer Daten oder Inhalte für das Training eines Sprachmodells schützen wollen. Hier fällt auf, dass sehr viele Standardgeheimhaltungsklauseln nicht nur Vertraulichkeitspflichten vorsehen, sondern auch den zulässigen Zweck, zu welchem Daten oder Inhalte genutzt werden dürfen, einschränken. Dies kann einem Training tatsächlich direkt entgegenstehen, spielt aber freilich bei öffentlich verfügbaren Inhalten grundsätzlich keine Rolle. Details hierzu erläutern wir ebenfalls in unserem Aufsatz.
David Rosenthal, Livio Veraldi
Wir unterstützen Sie bei allen Fragen zu Recht und Ethik beim Einsatz von künstlicher Intelligenz. Wir reden nicht nur über KI, sondern setzen sie auch selbst ein. Weitere Hilfsmittel und Publikationen von uns zum Thema finden Sie hier.
