
AI models – especially large language models – need to see a lot of data as part of their training so that they can map the concepts required for their function within their parameters. For this purpose, the companies that train the models primarily use publicly accessible content, and they do so without asking for permission. But is this allowed? We have analysed this with a focus on Swiss law, but our thoughts might also inspire the discussion at a European level. This 26th part of our blog provides an overview of the responsible use of AI. In any event: Switzerland seems to be a good place for training an LLM.
The idea that large language models memorise all the content that is shown to them during training is a popular misconception. This is neither the goal nor would it be particularly efficient. Rather, a model memorises those linguistic and factual concepts that it sees particularly frequently during training. This may well lead to content or even verbatim memorisation if the model repeatedly encounters the same slogan or sees a certain piece of information in numerous documents. However, this is not the normal case; after all, a model should generate new content, not recite individual items it has learnt. But where memorisation does occur, the question arises as to what this means from a legal perspective for the training and distribution of such models.
We have analysed this question in detail (including an assessment of the processing steps preceding the actual training) with a focus on Swiss law in connection with a corresponding project of the ETH AI Centre and have come to the conclusion that, despite all warnings, even memorisation does not stand in the way of training, especially of large language models with publicly accessible content. The details are set out in a scientific paper which I co-authored with my colleague Livio Veraldi. This paper recently appeared in Jusletter in German and Jusletter IT in English.
Adapt copyright law: Missed the target?
Copyright is causing the most discussion, mainly because at first glance it seems to be a particularly important issue: authors, creative professionals and other copyright holders do not want the fruits of their works to be used without their express consent and, above all, without remuneration from the major AI players. On the other hand, AI research and development fears that without access to content, the further development of the technology, and in the case of Switzerland, the Swiss economy, will be jeopardised.
These issues have to be decided by the legislators at a political level; however, it seems important at this point to note that the threat posed by US tech companies in the Swiss media sector is seen less in the training of language models with "old" copyrighted content, but rather in business models in which AI-supported applications refurbish current information – such as media headlines – as a raw material into new products without appropriate remuneration, but in competition with traditional media outlets. There is no need to adapt copyright law for these types of disputes because existing law already regulates these cases – especially where AI providers crawl and use content they find only behind paywalls and for which they have no authorisation.
Meanwhile, creative professionals are probably primarily concerned with AI as competition, which is able to produce content more cheaply and thus exert economic pressure on them. Other creative professionals do this too, and like AI, they also have to learn techniques by studying existing works or are inspired by them in their own work, but compared to AI, this all happens with much less leverage and is less effective. However, this is not a question of copyright infringement, but ultimately one of economic and legal policy – at least if the output of the AI does not infringe any copyrights. Opponents argue that Switzerland would only lose out from stricter regulation: Nothing is gained for creative professionals either, as the majority of models come from countries with "liberal" copyright regulations (USA, China) so Switzerland would lose its attractiveness as a location for the development of AI applications.
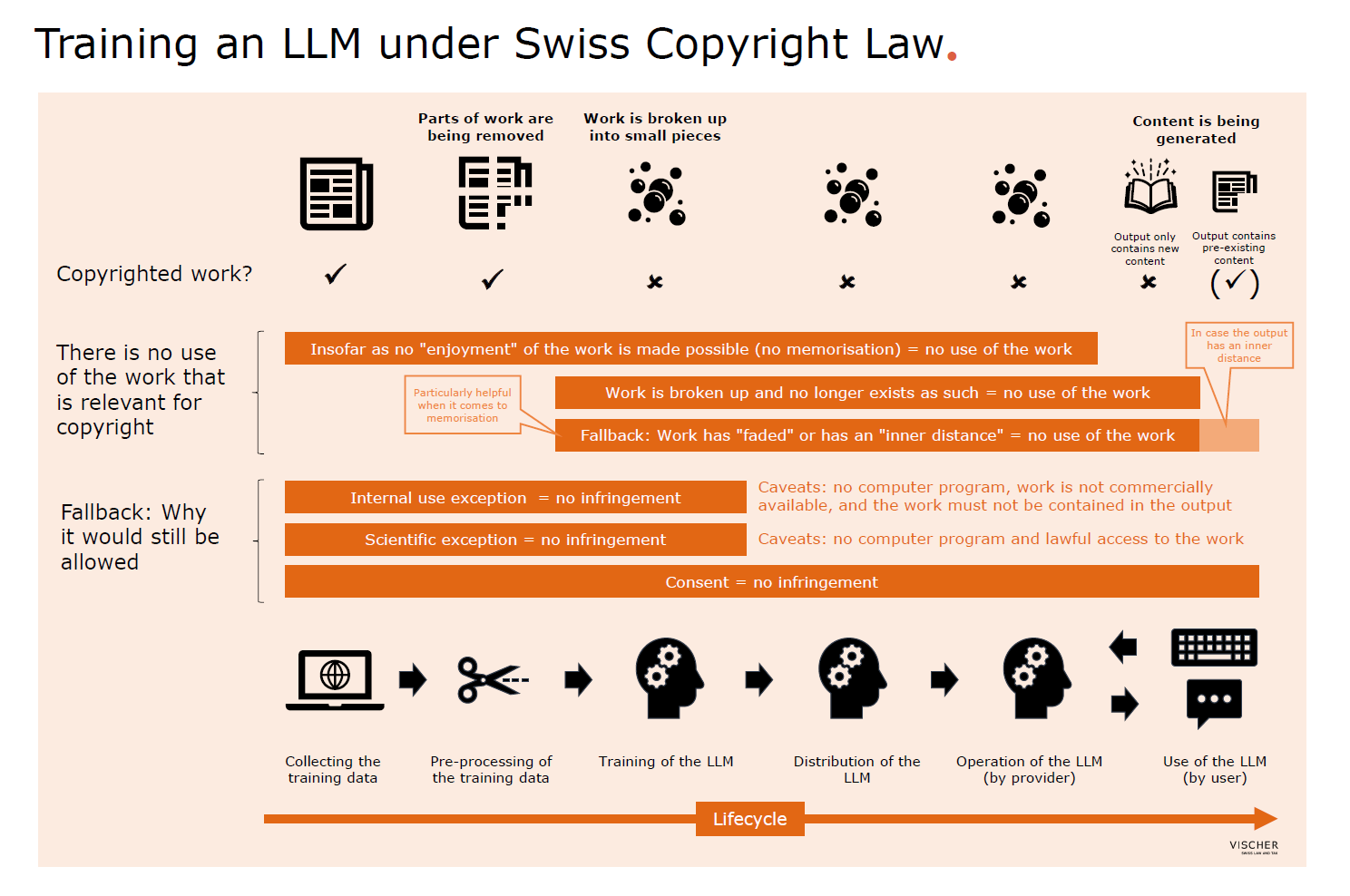
Copyright law: No copyright-relevant use of the work, scientific exception applies
From a purely legal perspective, our analysis showed that the permissibility of training large language models with publicly accessible content with and without memorisation can arise on three levels:
- The training of large language models with copyright-protected content is not a use of the work that is relevant for copyright. This – at first glance counterintuitive – conclusion results from an initial approach when we realise that copyright law covers only uses of the works that ultimately enable the actual enjoyment of these works by humans. However, when training large language models with copyrighted content, this is not the case. Even in the case of memorisation, these works are not technically available in the model in a form that enables their enjoyment by humans. Only in combination with a suitable prompt is it even conceivable that a certain output is generated in which the enjoyment of a work can be an issue at all. A second approach could be that we are dealing with the actual "enjoyment of a work" by the AI, which – analogous to human enjoyment of a work – must be free of copyright. Just as humans must first consume various works in order to be able to create their own works, AI is also dependent on consuming (sometimes copyright-protected) content during training in order to be able to generate any output at all. The question of how a model trained in this way is later used is – as with humans – a separate issue. The third approach we have outlined is based on the realisation that what is contained in the model after training can no longer be considered a work, even if it is memorised. One reason for this is that each work used for training is broken up into its (no longer copyright-relevant) individual parts or so called "tokens", and these pieces are mixed with the pieces of all other broken-up works to form a kind of "soup". Here too, the fact that, in the event of memorisation with the correct prompt, individual parts can be reassembled from this soup to form a work, as in a mosaic, does not change anything. Rather, this reassembly would be a new and independent generation or "recreation" of the work. And even if it were assumed that a work still existed in the model on a meta-level, so to speak, it would have to be conceded that such a work would fade into the background in the "soup" when viewing the model as a whole. It would therefore no longer be relevant under copyright law. At the very least, there will be sufficient "inner distance" between its presence as (linguistic or factual) knowledge in the model and the original to no longer be protected by copyright.
- The scientific exception (usually) applies. Even if the training of a large language model qualifies as a copyright-relevant use, it will regularly be covered by the so-called scientific exception (Art. 24d CopA). Although this exception presupposes lawful access to the content, any contractual prohibitions or conditions of use are likely to be regularly ineffective in this context. Furthermore, there is no opt-out right in Switzerland, as there is in EU copyright law within the framework of their "Text and Data Mining" (TDM) regulation. The key question in the context of this exception, namely whether the training of a language model constitutes a purpose of scientific research, is clearly to be answered in the affirmative according to our findings, as research is understood as a systematic, methodical search for new knowledge, regardless of the discipline – and this is precisely what the training of an AI model is about: it is intended to gain knowledge from the content presented to it. Commercial scientific research is also included in Switzerland. However, the scientific exception does not apply to computer programs. The other copyright exception that can apply is the internal use exception, which permits reproduction of works for internal information and documentation. One challenge here, however, is that it is not available for certain categories of work and the complete or substantial copying of a commercially obtainable work is not permitted. In practice, this can be countered with anti-memorisation techniques that remove parts of a text that are relevant to a human user without significantly impairing its value for the machine.
- There is (often) implicit consent of the rights holder. In practice, this legal basis is the weakest, as it can be actively counteracted by the rights holders. However, it may apply where content is published on the internet without corresponding countermeasures, because it can be argued that it can now be expected to be used for AI training.
Swiss copyright law is very similar to copyright law in the EU, so that the above considerations can also provide inspiration for the EU. One exception is Switzerland's decision not to implement the TDM regulation and in particular the opt-out right. This makes Switzerland a more attractive location for the training of AI models than the EU. The requirements of the EU AI Act for general-purpose AI models do not change this. The EU legislator did intend to enact a regulation that would force non-EU providers of such models to adhere to the TDM regulation when training their models. However, the relevant provision (Art. 53(1)(c) AI Act) was drafted carelessly and overlooked the fact that EU copyright law itself does not apply to training in Switzerland (or in the USA). Therefore, non-compliance with the TDM regulation cannot infringe the AI Act, either.
Conclusion: We see no urgent need to adapt Swiss copyright law. Some of the considerations can also be applied to EU copyright law, with the major exception that the latter with its TDM regulation is somewhat less liberal than the Swiss copyright law with its scientific exception.
Data protection law: Training data is usually only included in the model in anonymised form
A closer look at the data protection analysis shows that the training of large language models is by and large unproblematic under current data protection law. Here again, a distinction must be made between cases with memorisation (example: large language models know Donald Trump's birthday because they have seen it frequently enough in various sources) and cases without memorisation.
If memorisation occurs, the question of permissibility under data protection law arises in Switzerland at the latest at the level of justification, for the same reason that is the cause of memorisation: memorisation normally only takes place for public figures in whom there is a corresponding public or private interest, which causes their personal data to be reported in public in correspondingly large numbers. Only in these sort of cases does information normally become statistically relevant or frequent enough to be included in the model where training relies on public data. If the public interest dwindles thereafter, the probability that a prompt will ever be formulated that leads to the generation of corresponding output will also vanish. Without such a prompt, however, there is no output and therefore no personal data. We have already explained this in detail in our Blog 19 and Blog 21, and in the meantime this view seems to be gaining acceptance.
If there is no memorisation, it is even more obvious why the use of personal data for training is in essence not an issue: although personal data is used when training is carried out with public content, the individual pieces of personal data will not survive the process, but be aggregated in the language model into a form of superordinate language and general knowledge. In other words: it is effectively anonymised. Even if – as shown in our article – a violation of the processing principles (e.g. the principle of transparency) were assumed, this violation would be justified as a "processing for purposes not related to specific persons", which is one of the cases expressly provided for by Swiss data protection law. Also, such processing will usually be compatible with the main purpose of the data.
The principle of proportionality is usually not a problem either: Firstly, with language models, the more data the better, and secondly, the personal data as such is broken up into small pieces by the training, like the ingredients of a soup, which can no longer be identified individually, but contribute to the overall flavour. The training of a language model also does not appear to be unfair in other respects either: the individual personal data is usually not memorized. Rather, it is analysed as part of text in order to permit the model to derive linguistic and factual knowledge. This is a legitimate purpose, which the legislator – as shown in copyright law – is actually promoting. The fact that incorrect data is also processed does not detract from this either. Firstly, incorrect data is usually not memorised because it does not occur sufficient frequently, and secondly, where it does, the training does exactly what the purpose requires: it models what has been seen in the training. In this respect, the data processing itself is accurate. In such cases, the real problem is not the model, but its use. The same is true for hallucinations: It is not the model that contains false information, it is the model's alignment that pushes it to come up with an answer even where it has no factual basis for doing so.
Our analysis is based on Swiss law but can also be applied to a large extent for the GDPR, with the restriction that a legal basis is required per se for the training there. This will regularly be legitimate interest. If special categories of personal data cannot be completely avoided in training, as a legal basis either publication by the data subject (where applicable) or qualifying it as research is particularly suitable. However, we did not get to the bottom of this in our article. The GDPR is irrelevant for the training of language models carried out in Switzerland by institutions in Switzerland.
Do not forget unfair competition law and contract law
We have also taken a closer look at unfair competition law, which, alongside copyright law, has been somewhat unjustly overshadowed in the debate on AI training. Unfair competition law also provides for regulations against the unauthorised exploitation of other people's work products. The realisation that the training of language models leads to the abstraction of information from the training data also plays a decisive role here. This fact distinguishes the training from the adoption and exploitation of a specific intellectual product as such. It is therefore not a work product that is utilized in the case of training an LLM. Rather, the training "only" makes use of the findings from someone's work product – and only if they are statistically relevant, i.e., are part of general linguistic and factual knowledge. Such knowledge cannot be monopolised.
But what happens if the operator of a website adds a machine-readable notice prohibiting crawling and scraping? Such notices do not necessarily prevent the training of a language model. As shown, copyright law works with concepts that do not depend on the consent of the rights holder. Under data protection law, a crawler ban may qualify as an objection, but it would have to come from the data subject themselves, which is not usually the case, and even where it does apply, there is usually an overriding interest. Under unfair competition law, the existence of a crawler ban is usually not decisive.
This leaves contract law as a means for those who want to protect themselves against the use of their data or content for the training of a language model. It is notable that many standard confidentiality clauses not only provide for confidentiality obligations, but also restrict the permissible purpose for which data or content may be used. This can actually directly conflict with training but is of course generally irrelevant in the case of publicly available content. We also explain the details of this in our article.
David Rosenthal, Livio Veraldi
We support you with all legal and ethical issues relating to the use of artificial intelligence. We don't just talk about AI, we also use it ourselves. You can find more of our resources and publications on this topic here.
